경량화 시 성능이 급감하는 RetinaFace의 한계
RetinaFace는 고성능(ResNet-50 백본)과 경량화(MobileNet-v1 백본) 사이의 극심한 성능 격차 문제가 있었습니다. 우리는 MobileNet-v1로도 고성능을 낼 수 있는 구조적 개선을 목표로 삼았습니다.
문제 1: 성능 격차
백본을 ResNet-50에서 MobileNet-v1으로 교체 시 AP가 약 10 포인트 급감합니다. 경량화와 고성능을 동시에 달성할 수 없습니다.
문제 2: 병목 구조 (Detection Head)
RetinaNet의 경량화 후속 논문 분석 결과, Detection Head에 FLOPs가 집중됨을 확인했습니다. 중간 레이어의 정보 전달 효율을 높이면 경량화 및 성능 개선이 가능할 것이라고 판단했습니다.
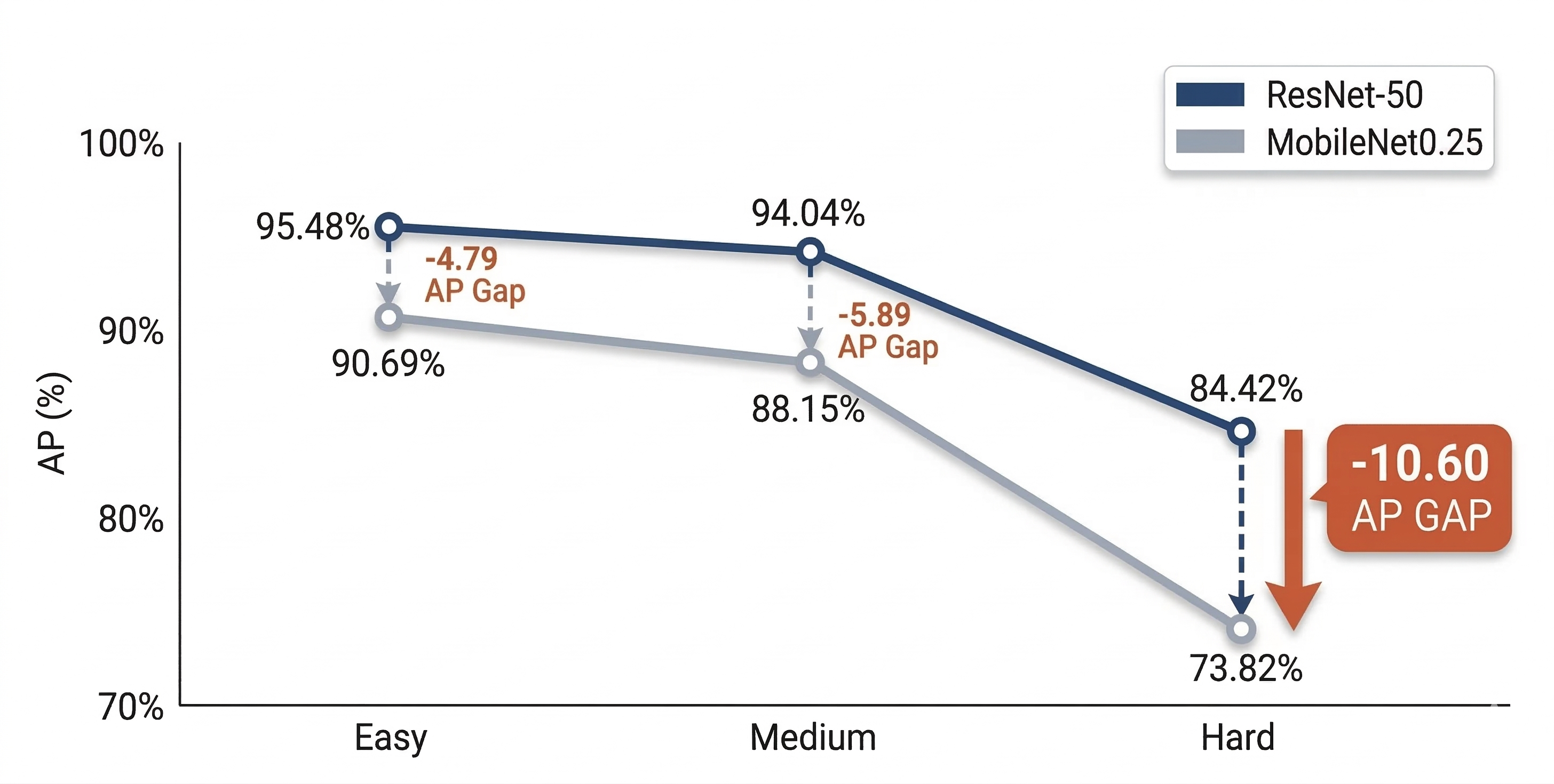
ResNet-50 vs. MobileNet-v1 성능 비교 (WiderFace Benchmark)
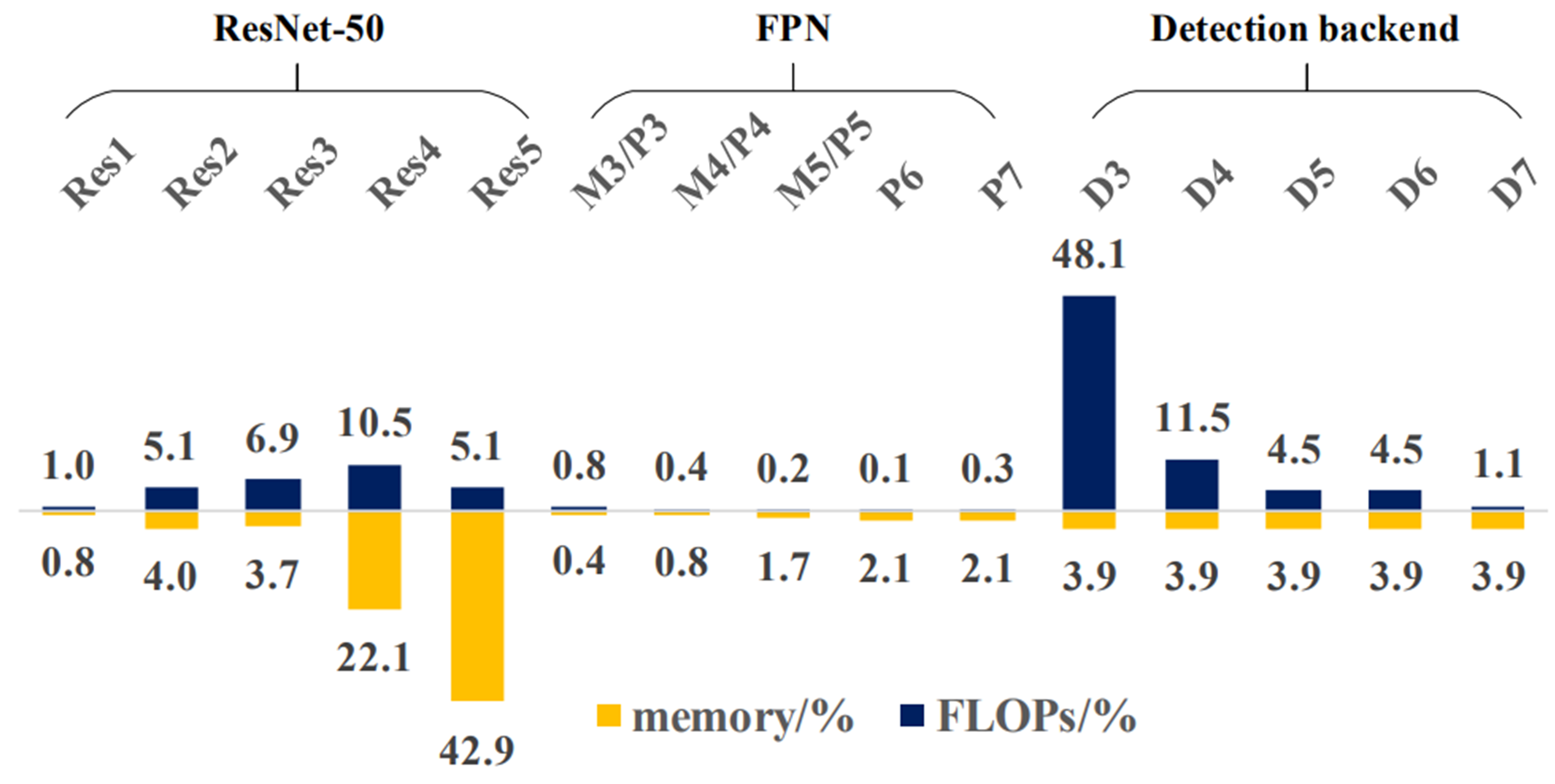
레이어별 FLOPs/Memory 분포 분석 — Detection Head 에 집중
4개의 커스텀 모듈로 재설계한 탐지 파이프라인
기존 구조
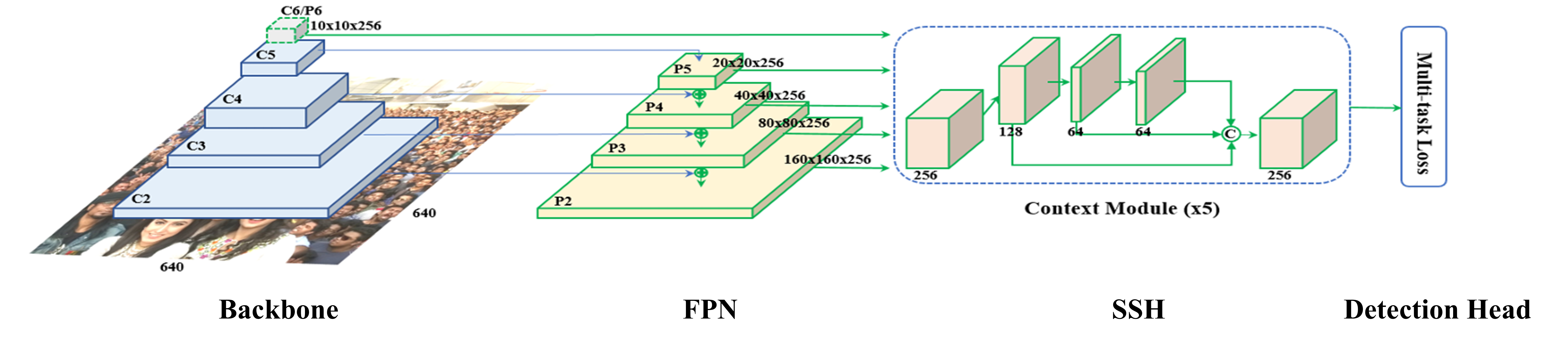
기존 RetinaFace 아키텍처 전체 구조도
개선 구조 (Ours)
* 일부 모듈 Deformable Convolution 활용
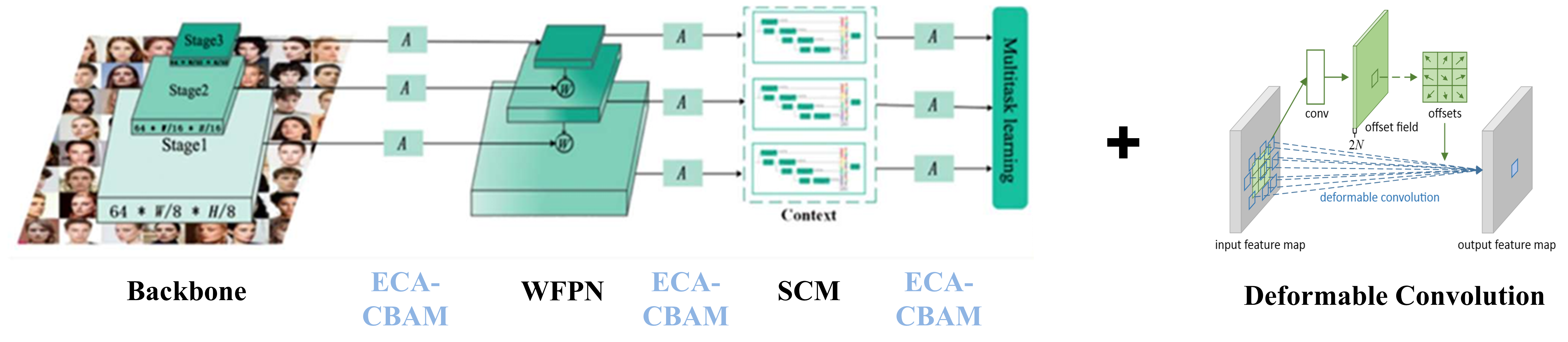
제안된 아키텍처 전체 구조도
핵심 개선 모듈 상세
FPN (Feature Pyramid Network) → WFPN (Weighted Feature Pyramid Network)
기존 FPN은 고수준(high-level) 특징을 저수준(low-level) 특징으로 단순 합산(sum)하여 흘려줍니다. 이 과정에서 두 특징의 중요도가 동일하게 취급되어 정보 손실이 발생합니다.
WFPN은 두 특징 사이에 Learnable Parameter를 도입하여, 고수준/저수준 정보의 기여도를 동적으로 조절합니다. 이를 통해 정보 손실을 줄이고 특징 피라미드의 표현력을 향상시킵니다.
out = high_feat + low_feat
// WFPN (Ours)
out = w₁ × high_feat + w₂ × low_feat // w₁, w₂ are learnable
ECA-CBAM (Efficient Channel Attention CBAM)
중간 레이어 간 정보 흐름을 정제하기 위해 Attention 모듈을 WFPN 전·후, SCM 후 총 3곳에 삽입했습니다.
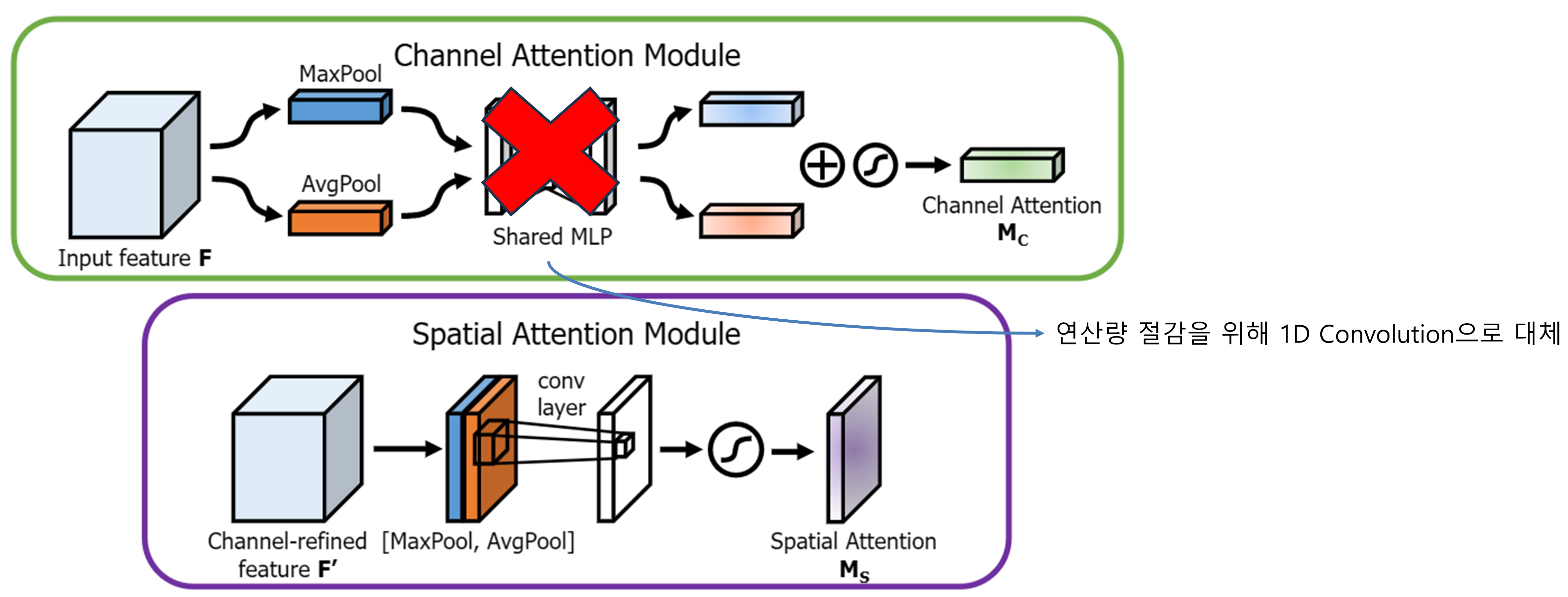
[Figure 5] ECA-CBAM 모듈 구조: 1D Conv를 활용한 효율적인 Attention 메커니즘
SSH → SCM (Shuffle Context Module)
기존 SSH는 3×3, 5×5, 7×7 Convolution으로 다양한 receptive field를 추출하지만, 채널 수가 크기 때문에 연산량이 상대적으로 큽니다.
| 항목 | 기존 SSH | SCM (Ours) |
|---|---|---|
| Receptive Fields | 3×3, 5×5, 7×7 | 3×3, 5×5, 7×7, 9×9 |
| 채널 수 | 그대로 유지 | 축소 (연산 절감) |
| 결합 방식 | Concatenation | Channel Shuffle |
채널 Shuffle 과정을 통해 더 넓은 receptive field의 정보를 효율적으로 결합합니다.
Deformable Convolution
WFPN, SCM 모듈 내 일부 Convolution을 Deformable Convolution으로 대체했습니다. 표준 Conv는 격자형 고정 위치를 샘플링하지만, Deformable Conv는 offset 기반 동적 샘플링으로 얼굴의 변형(포즈, 가림, 소형 얼굴)에 robust하게 대응합니다.
어려운 환경일수록 더 벌어지는 성능 격차
WiderFace 데이터셋 기준으로 RetinaFace와 제안 모델의 성능을 비교합니다. 우리의 모델은 RetinaFace보다 연산량을 2.6% 절감하면서, 모든 케이스에서 탐지 성능을 개선했습니다. 탐지가 어려운 Hard case에서 격차가 더욱 크게 벌어집니다.
| Method | Easy | Medium | Hard | Flops | Parameter |
|---|---|---|---|---|---|
| RetinaFace | 90.69% | 88.15% | 73.82% | 1.030G | 426,608K |
| RetinaFace + WFPN | 90.66% | 88.38% | 73.96% | 1.030G | 426,738K |
| RetinaFace + WFPN + SCM | 90.89% | 88.36% | 74.10% | 999.066M | 415,122K |
| RetinaFace + WFPN + SCM + ECA-CBAM | 90.82% | 88.45% | 74.85% | 1.003G | 416,049K |
|
RetinaFace + WFPN + SCM + ECA-CBAM (Deformable Conv, Ours) |
91.88% | 89.74% | 76.89% | 1.003G | 599,406K |
핵심 결과
Easy → Medium → Hard로 갈수록 성능 향상폭(+1.2 → +1.6 → +3.07 AP)이 커지는 패턴은, 우리 구조가 작고 변형된 얼굴에 특히 효과적임을 보여줍니다. Deformable Conv와 더 넓은 Receptive Field(9×9)가 주요 요인으로 분석됩니다.
정성적 평가 — 실제 이미지 탐지 비교

Baseline RetinaFace — 탐지 누락 존재

Ours — 기존 모델이 놓친 얼굴도 탐지 성공

Baseline — 확대 비교 (소형 얼굴 탐지 실패)

Ours — 확대 비교 (소형 얼굴도 탐지 성공)