모델이 손상이 아닌 '마킹'을 보고 있다
차량 유리 손상 이미지를 분류 AI를 개발하면서, 모델이 실제 손상 부위가 아닌 다른 시각적 요소에 의존하여 판단하는 두 가지 구조적 문제를 발견했습니다.
문제 1: Data Distribution (Overfitting)
손상 식별을 위해 표기한 Marking이 클래스 간 불균형하게 존재합니다.
- ·Repair 이미지 중 Marking 포함 비율: 9.7%
- ·Replace 이미지 중 Marking 포함 비율: 54.5%
- ·모델이 "Marking 있으면 Replace"라는 Shortcut을 학습할 위험 ↑
문제 2: Attention Misalignment
손상 주변에 무관한 배경(사람의 손, 차량 부품 등)이 다수 존재합니다.
- ·배경이 모델의 Attention을 손상 부위로부터 분산
- ·XAI(Grad-CAM) 분석 시 비관련 영역에 집중하는 현상 확인
- ·모델의 의사결정 결과를 신뢰하기 어려운 상태

데이터 예시. (Top) Repair, (Bottom) Replace

Attention 결과. (Left) Input, (Right) Grad-CAM
결론적으로, 두 문제의 공통점은 모델이 손상 부위에 집중하지 못하게 만들며, 이는 곧 모델 결과를 신뢰할 수 없도록 한다는 것입니다.
두 가지 Pre-hoc 기법의 순차 적용
모델 아키텍처가 아닌 데이터 자체를 정제하는 Data-Centric 접근법을 채택했습니다. 두 가지 독립 파이프라인을 순차 적용하여 최종 분류 모델에 입력합니다.
GAC (Generative Annotation Cleaning)
Gemini 2.5 Flash 모델에 이미지를 입력하고, instruction-guided 방식으로 배경은 유지하면서 손상 주변의 Marking만 선택적으로 제거합니다.
YOLO-Crop (ROI Focusing)
YOLO (v2/v4/v5/v8)로 손상 부위를 탐지하고, 해당 영역만 크롭합니다. 이를 통해 배경을 물리적으로 제거하여, 모델이 손상에만 집중하도록 강제합니다.
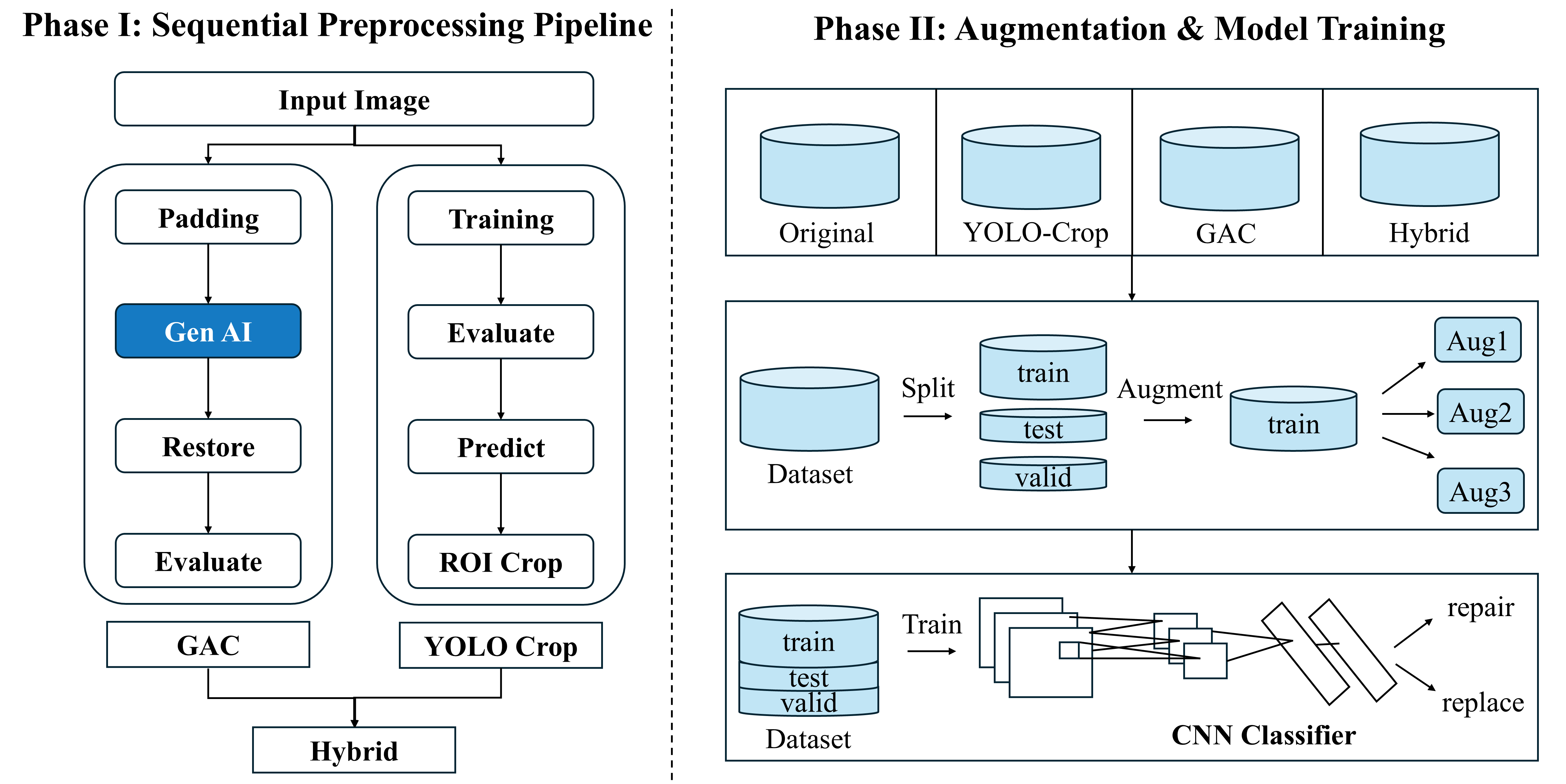
전체 파이프라인: Input → GAC (Marking 제거) → YOLO-Crop (ROI 추출) → CNN Classifier
파이프라인 단계별 데이터 변환 예시

① Original Input

② GAC 적용 후

③ YOLO-Crop 적용 후

④ Hybrid (GAC + Crop)
3가지 검증 실험 설계
GAC 성능 검증 — Self-Supervised Protocol
GAC의 성능을 정밀 측정하기 위한 자체 프로토콜을 설계했습니다. 마킹이 없는 이미지를 GT로 설정하고, 마킹을 추가한 뒤 GAC의 복원 결과와 다양한 Anchor를 비교합니다.
평가 지표
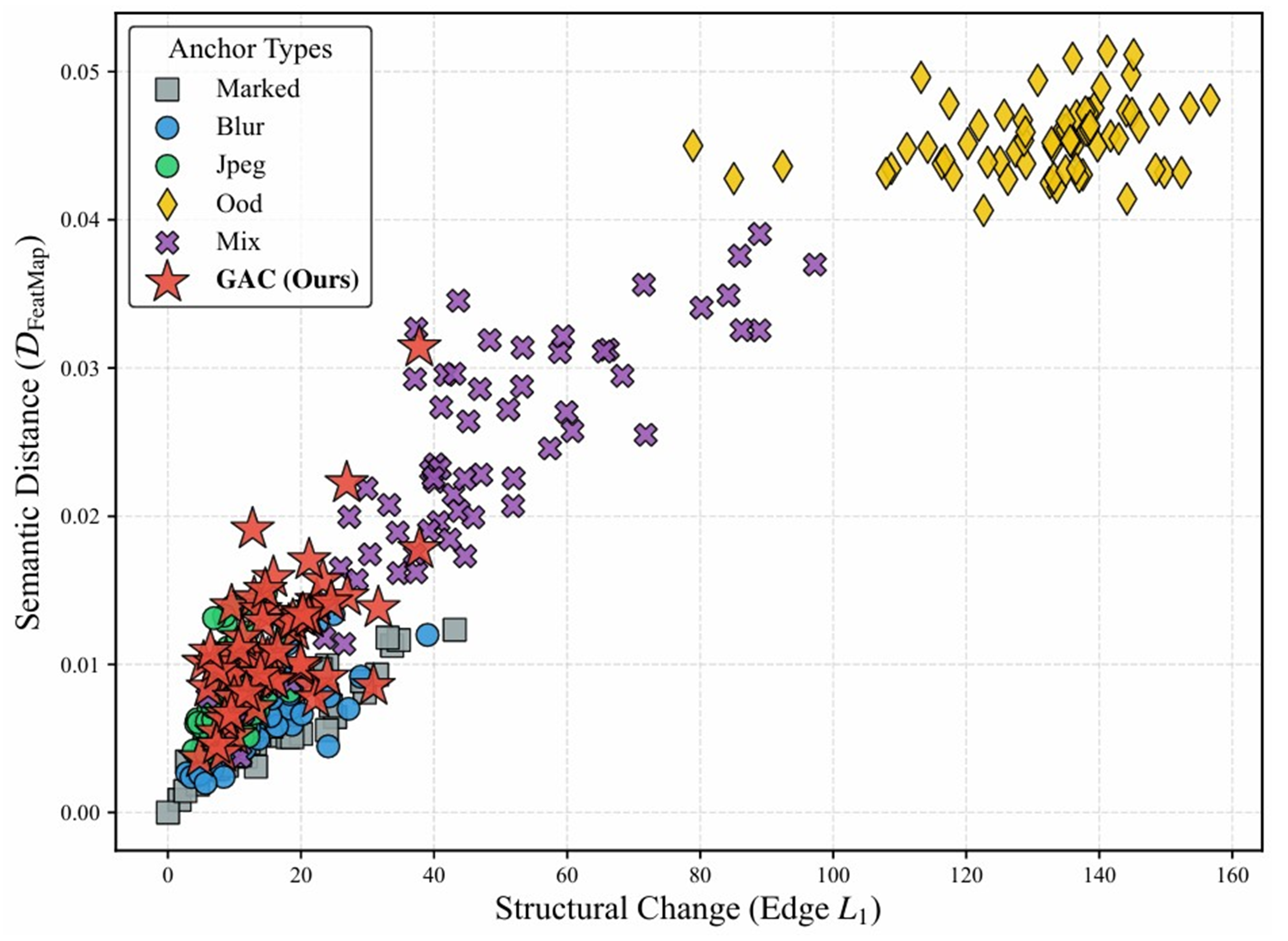
GAC 성능 검증: Scatter Plot (Edge L1 vs. Feature Map Distance)
핵심 결과
GAC는 원본과 거의 차이가 없는 약한 Blur, JPEG 집단과 유사한 군집을 형성하며, 생성형 AI의 실무 도입 가능성을 확인했습니다.
YOLO-Crop 필요성 검증 — 비교 실험
원본 이미지에 배경 제거의 다양한 방법(GAC / Blur / Black-out / YOLO-Crop)을 적용 후, 동일한 분류 모델의 성능을 비교하여 YOLO-Crop의 채택을 검증합니다.
| Dataset | Strategy Characteristics | Accuracy (%) |
|---|---|---|
| DGAC | Markings Removed, Background Kept | 86.74 ± 0.010 |
| Dblur | Background Blurred (Full FOV) | 89.38 ± 0.012 |
| Dblack | Background Blacked-Out (Full FOV) | 89.07 ± 0.015 |
| Dcrop | Background Removed + Geometric Focusing | 97.46 ± 0.005 |
핵심 결과
GAC / Blur / Black-out 기법은 정확도 90% 미만에 머물렀으나, YOLO-Crop은 97.46%로 타 방법론 대비 월등히 뛰어난 성능을 보였습니다.
Attention Alignment 검증 — Grad-CAM 시각화
Original과 YOLO-Crop 데이터셋으로 동일한 분류 모델을 학습시키고, 동일한 이미지에 대하여 Grad-CAM 시각화를 통해 Attention Alignment를 비교합니다.
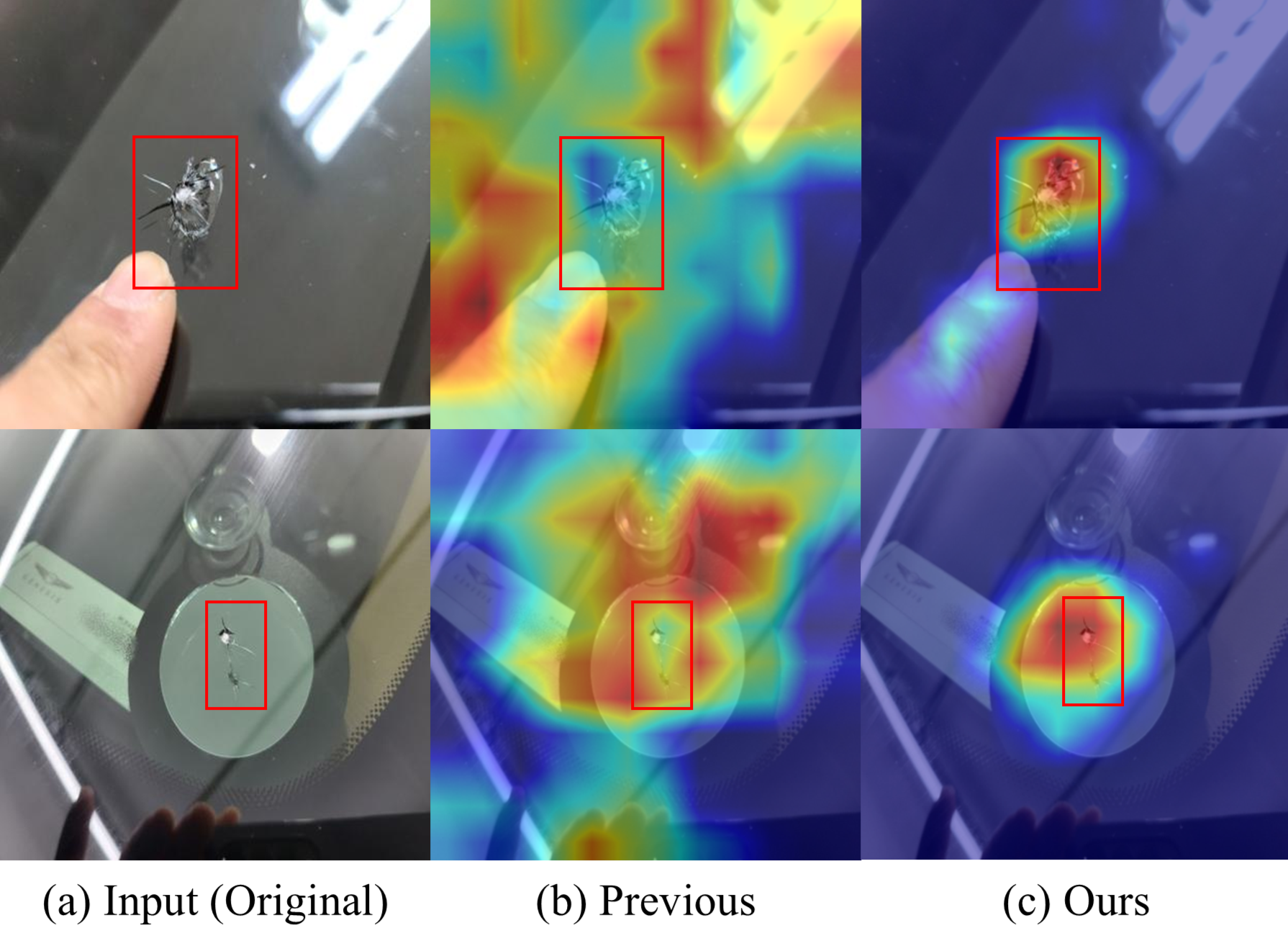
Original 데이터에 대한 Attention Alignment
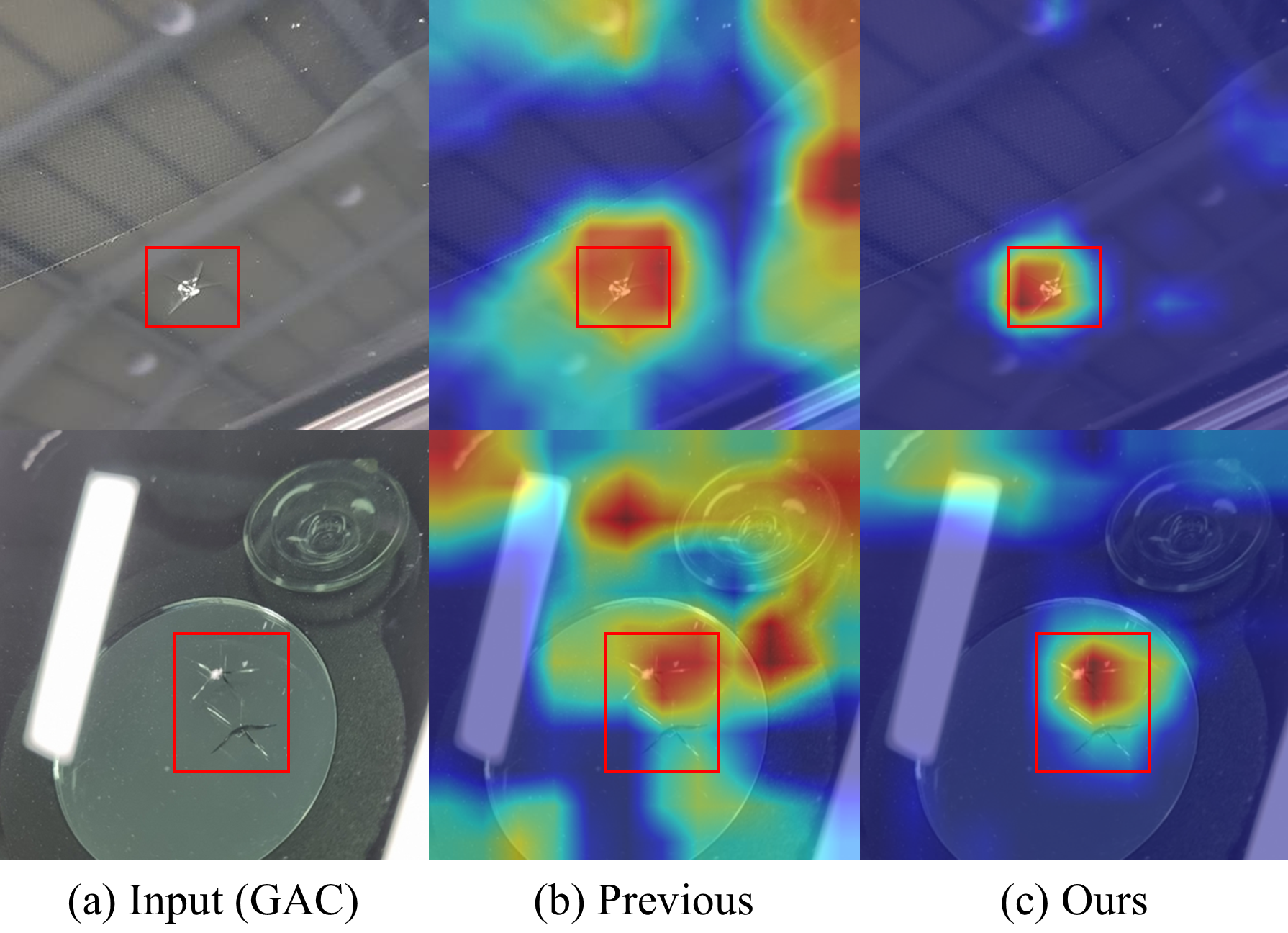
GAC 데이터에 대한 Attention Alignment
핵심 결과
주위 배경으로 분산되지 않고, 손상으로 Attention이 Alignment되는 것을 확인했습니다. 또한, 동일 실험을 GAC 데이터셋에서 수행했을 때에도 같은 결과를 보임을 통해 배경이 손상의 Attention을 분산시키는 현상은 Marking의 유무와 관계가 없음을 입증했습니다.
신뢰할 수 있는 분류기 달성
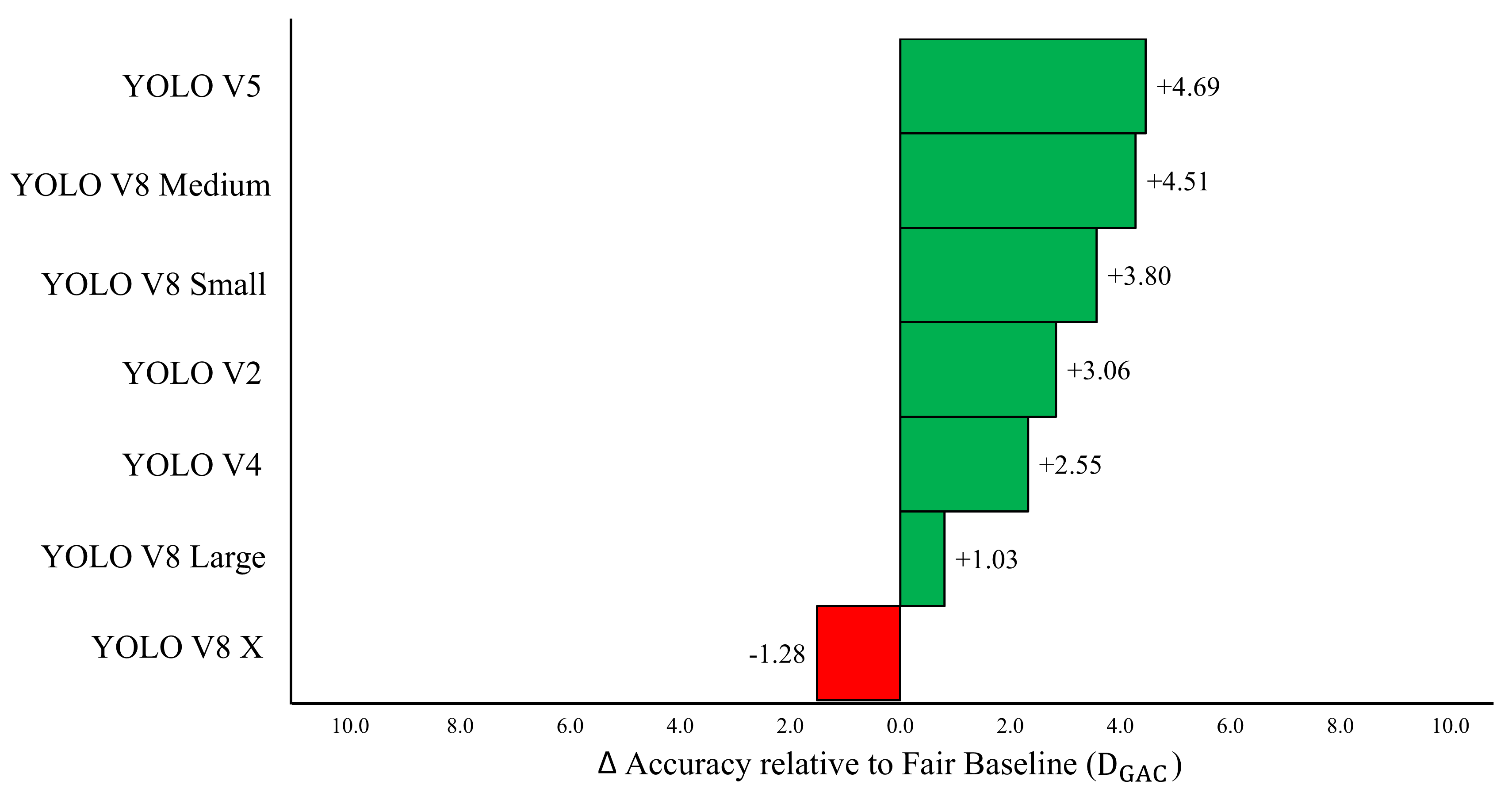
방법론 적용 후 분류 정확도 비교 결과 (Baseline: 88.71%)
MLOps 구현 및 배포
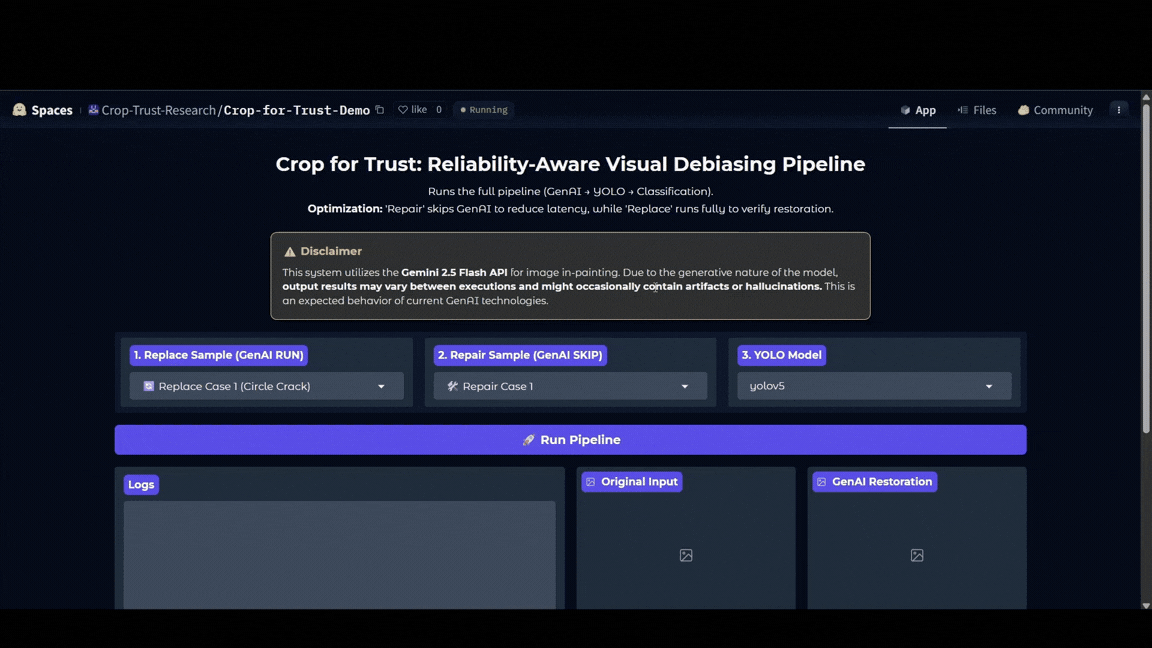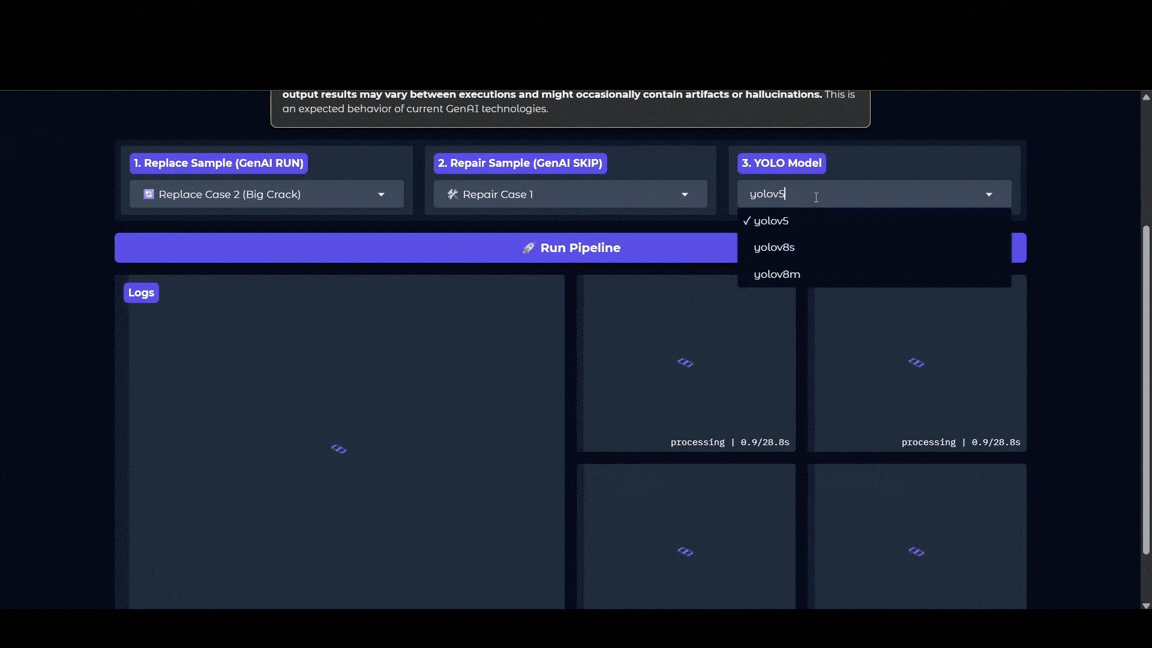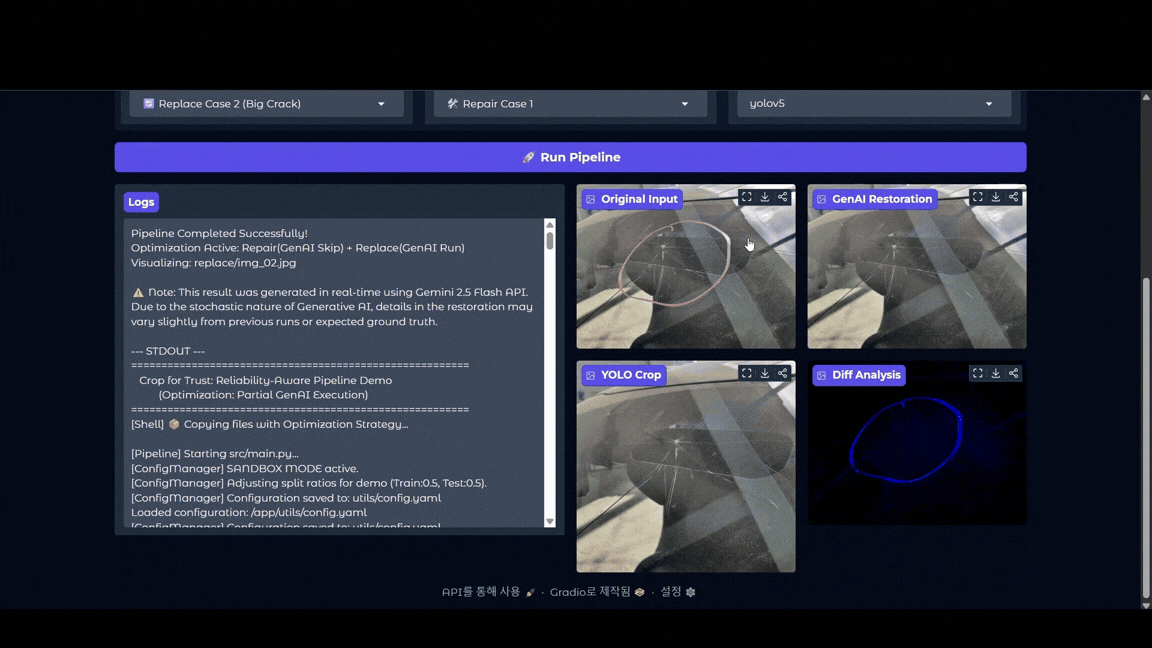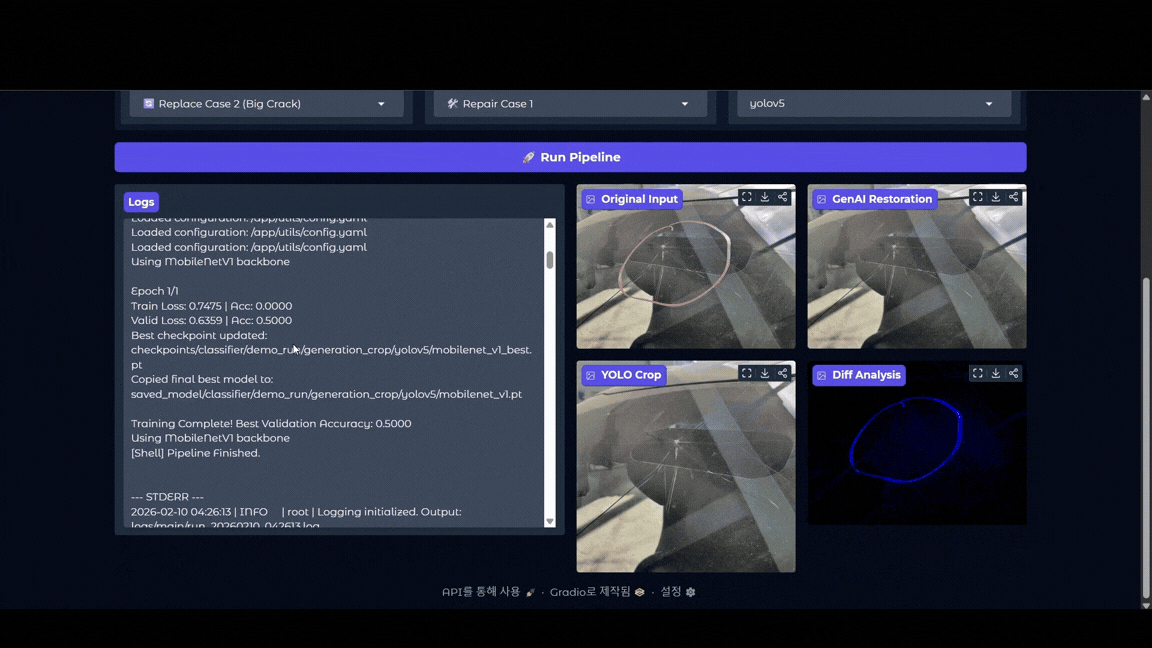
Streamlit 웹 데모 시연 (Hugging Face Spaces 배포)